Contents
Costs of Cached Function Calls
Every time the SDL code in a Vesta build calls a cached function, a lookup is performed to the Vesta cache server. Unfortunately, cache lookups are not free. They take time, network bandwidth, CPU resources on the client evaluating the build, and CPU and I/O resources on the server running the cache daemon. So it's a good idea to optimize them out when possible.
Optimizing the Common Case with Balanced Call Trees
Suppose you have a function that takes in a list of files to process. Each one will be processed by calling another cached function (perhaps just _run_tool). Imagine a build that calls this function with a list of 100 files. As a user is working, suppose they have changed just one file since the last time they built. What cache lookups would be performed and what would be their result? Or to put it another way, what would the call tree of cached functions look like?
We would cache miss on our function that takes a list of 100 files. We would then perform 100 cache lookups, 99 of which would be cache hits and one of which would be a cache miss (for the single file that the user edited since they last built). Here's a graphical representation of this rather simple and flat call tree:

That's 101 cache lookups total. This seems like a lot for changing one file. If we could eliminate some of them, the build will complete faster while using less resources on both the client and the server.
Luckily there's a simple divide and conquer technique we can use to improve this situation called balanced call trees. When our function to process multiple files is called, we'll first check to see how many files were supplied. If more than a small number of files were passed to our function, we'll divide them in half and call our function recursively with the two halves.
Suppose we chose to divide the files up if there were more than 10 of them. With 100 files we would divide them in half until we reached groups of 6-7 files each. Now our call tree looks like this:
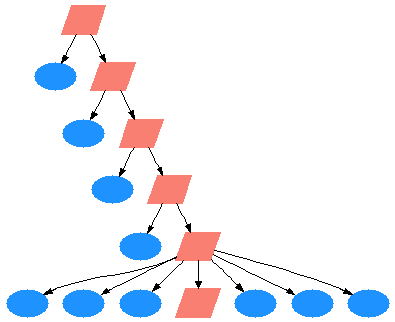
Now instead of 101 cache lookups, we have just 16. That's a significant improvement. The user should definitely notice the improvement in run-time.
Of course if most of the 100 files are modified or if the whole build is a cache miss, this method could result in more cache lookups than before. However we're trying to optimize for the common case of a user working in the normal edit-build cycle.
Examples
There are two key examples of this technique in the /vesta/vestasys.org/bridges/generics:
./generic/compile implements exactly what's described above. It's used by the c_like bridge for compiling C/C++ source files.
./generic/map and ./generic/par_map act like the primitive functions _map and _par_map, but with caching using balanced call trees.