Contents
A Motivating Example
Suppose Jill replicates /vesta/example.com/foo/10 from the main project repository. She disconnects from the network and wants to make some changes locally so she creates a foreign checkout:
% vcheckout -F /vesta/example.com/foo Creating session /vesta/jill.example.com/example.com/foo/checkout/10.jill_jlaptop.example.com.1 Making working directory /vesta-work/jill/foo
She makes some changes and takes a few snapshots as she works, until she's satisfied with her work:
... % vadvance /vesta-work/jill/foo Advancing to /vesta/jill.example.com/example.com/foo/checkout/10.jill_jlaptop.example.com.1/7
In the mean time, someone else has checked in /vesta/example.com/foo/11.
Now Jill wants to push her changes back into the mainline, so she does a merge operation and checks in the result of the merge as /vesta/example.com/foo/12.
What if someone wants to see where the change in foo/12 originated from? What if Jill doesn't replicate her change back to the main repository? She might not even have permission to do so. We know her laptop repository may not be accessible on the network. Is the only way to get at the original change to send Jill an e-mail and hope she's around?
Even if she has replicated her snapshot to the main repository, how do you find it? Is there an attribute on foo/12 to tell you what was merged to create it, or do we simply rely on Jill to mention that in the checkin comment?
Why is these interesting questions? Suppose there was more significant development in the disconnected repository before Jill re-connected and merged. Suppose foo/12 is broken in some way, but Jill's original change isn't. It could be important to look at the two parallel changes prior to the merge operation.
(This example is based on some discussion on the #revctrl IRC channel.)
Merging Needs Accurate Historical Records
Historical records are required by all but the most rudimentary merging algorithms.
There is a method called 2-way merge which can work from simply two different states. However this requires manual resolution of any differences between the two states, which is very labor intensive for users. It is not considered very useful.
A method called ThreeWayMerge merge has been in use for a long time in systmes like RCS, CVS, and others. It involves finding a common ancestor and comparing the files on both sides to that common ancestor. This requires traversing history backwards from the two versions to be merged to find the common ancestor.
Unfortunately, ThreeWayMerge merge only works acceptably in extremely limited and disiplined cases of branching and merging. Any one of a number of fairly simple and reasonable merge sitations (repeated merges, CrissCrossMerge, etc.) can cause ThreeWayMerge merge to either force the user to do more manual resolution of conflictst or even do the the wrong thing (silently discarding changes in some cases).
More advanced textual merging algorithms such as PreciseCodevilleMerge (which we've actually prototyped in Vesta) require the entire history back to not just any common ancestor, but the common ancestor through which all ancestry paths lead (which some people call a dominator).
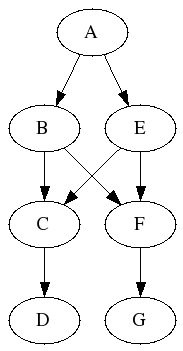
In this history, any of A, B, or E could be considered a common ancestor of D and G. However only A is a dominator. A merge algorithm like PreciseCodevilleMerge would need the file contents at every node in this entire sub-graph to merge D and G.
Note that the records needed by such advanced merge algorithms must also include records of when previous merges were performed. A version combining two sets of changes (C or F above) has both parent versions recorded.
Problems In Vesta
Unfortunately, Vesta does not currently maintain historical records which are either accurate or complete enough to support advanced textual merging. Vesta really only guarantees to keep immutable copies of individual points in history. This stems from the design focus on consistent and repeatable builds, which requires an immutable store of individual states but not records about how they came about.
There are several problems we will need to address in Vesta to support advanced merging:
Vesta's replication design explicitly allows a repository to contain a fragmented history. For example, from the graph above a repository might contain only versions A, E, C, and G. The other versions might be available from another replica somewhere on the network, or they might not. Even if all those versions were in packages/branches mastered in one repository, that repository is only required to know the set of names that exist (A through G), not to know their contents.
The record of each version's direct ancestor is in a mutable attribute set by vcheckin. This makes it unreliable, little more than an annotation. It really needs to be recorded immutably as part of the version.
A version may actually be stored internally as a delta of changes over some previous version. (See the deltaOnly parameter to VestaSource::list and VestaSource::getBase.) However this is primarily an internal mechanism for saving space and there's no guarantee that a version is recorded as a delta. In a replica with a fragmented history each version may be a complete copy with no such base pointer.
- Merges need to be recorded as ancestry. They need to be recorded just as reliably as the version upon which a hand edit is based.
- We could distinguish "merged with" as a distinct relationship from "derived from", but merge algorithms don't recognize the distinction so it would be purely an annotation for users.
Partial Replication vs. Ancestry
As discussed above, to support merging we need to ensure that we have a complete historical record. This means that replication will need to understand ancestry and follow it, replicating a complete history graph to each repository.
For example, suppose repository X has a history like this:

Now suppose repository Y has a branch based on one of these versions, which contains a non-exclusive checkout:
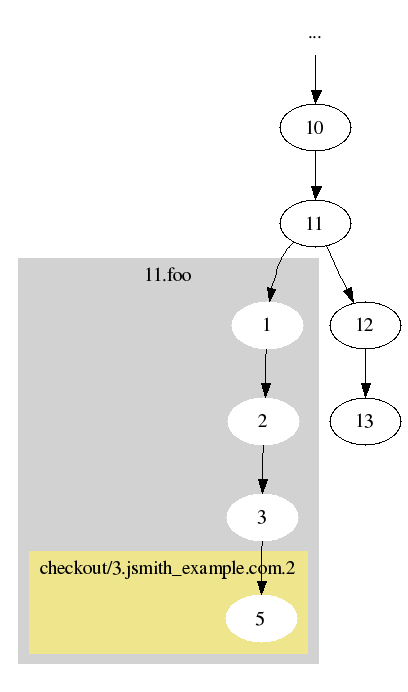
If someone wants to replicate 11.foo/checkout/3.jsmith_example.com.2/5 to repository X, currently they can replicate that version in isolation. To preserve a complete history, replication would need to follow the ancestry backwards until finding a version which already exists at the destination. It would then copy all of the intervening history (11.foo/1, 11.foo/2, and 11.foo/3) to the destination in addition to the requested version.
This would ensure that the destination does not have a fragmented representation of the evolution up to the version in question. This is necessary to enable anyone at repository X to perform a merge of 11.foo/checkout/3.jsmith_example.com.2/5 and 13. It's worth mentioning that repository Y may be inaccessible when the user wishes to perform such a merge operation. Even if it is available, keeping a complete history locally will avoid the merge tool operating slowly by contacting remote repositories over the network to traverse the history.
Note that in a more complex history that includes version with multiple parent versions (i.e. previous merges), the replication code would need to replicate back along all ancestry paths, not just the first one which reaches a version already present in the destination repository.
One problem with doing this currently has to do with the naming of versions. What if the 11.foo branch exists under a different hierarchy below /vesta? Perhaps it's a foreign branch created with vbranch's -F flag (introduced recently). Do the #replicate-from attributes in repository X allow that hierarchy to be replicated from repository Y? Of course they probably do if someone is going to replicate 11.foo/checkout/3.jsmith_example.com.2/5. However what if the branching is more complex and the ancestry passes through multiple different named hierarchies before reaching a version already present in the destination repository?
Always Replicate Ancestry?
Should replication always be required to follow ancestry like this?
Requiring that every replica contain the entire version history may take up more storage space. Requiring the replicator to copy additional versions may take more time and network resources. Perhaps the 11.foo branch just contains a bug-fix that the user at repository X is only interested in building and testing without doing any development which might require merging. In that case, the additional time to replicate and storage space at the destination repository might be wasted.
Perhaps the user could tell the replicator whether they wish to follow ancestry or not. Or, the replicator could attempt to guess whether the user is interested in building or active development based on the replication directives. A reasonable first guess might be that any version explicitly mentioned in a + directive should have its history replicated, but versions added via the @ (build imports) directive should just be copied without their history.
However, whatever method is used to make such a choice about replicating history, whether explicitly specified by the user or implicitly guessed by the tool, seems likely to be wrong at least some of the time. This means allowing the possibility that insufficient history is available to perform a merge operation. If we allow such "insufficient history" merge failures to happen, we should carefully consider the the consequences:
- Such merge failures would inconvenience the user.
- The occurrence of such merge failures will seem random and arbitrary to a normal user.
- Such failures might not ever be resolvable if portions of the history are lost or never made available to those parties interested in merging.
Vesta would be the only version control system with such failures in its merge system. This could be a significant reason for people to decide not to use Vesta.
Because there is a simple way to avoid such merge failures (always replicating a complete history), it seems prudent to do so. But then Vesta becomes (the only?) system that forces a full replication just to do a build. We need to balance the merge functionality against the basic version control and build functionality. This could also be a significant reason for people to decide not to use Vesta.
We can definitely mitigate the additional costs in terms of storage and replication latency.
First of all, even today replicating a complete history would enable the repository to store each version's directory more efficiently in VMemPool space. Replicating every other version, or even just replicating them in the reverse order of history, will cause each directory to be a complete copy at the destination rather than a delta over a base directory and thus consuming more space. If replication always copies the full history, the repository can always store versions as deltas. This would of course also reduce the latency of the copying operation.
Secondly, we can implement compression of immutable source files, or even delta compression. There are readily available libraries of code to do both. In fact, having a complete history would make delta compression more feasible. We could also use delta compression when sending files for replication, which would save more network bandwidth.
Finally, the current replication protocol has a number of inefficiencies which we can eliminate. We will probably need to re-design the replication protocol anyway to facilitate following ancestry. I am confident that we can make it significantly more efficient than the current protocol even if we always copy full history.
Partial History, or All History?
The most conservative approach of replicating ancestry would be to always replicate the entire history, back to the first version (one with no previous version). This would always ensure that there would be sufficient history to merge between any two parallel versions.
However in most cases a new developer wouldn't need the complete history back to the beginning of time. They might need some recent history, but in general history becomes less useful the older it gets. So it would be nice if there was an alternative to replicating back to the beginning of time.
Suppose for example we have a reasonably long history in one repository:
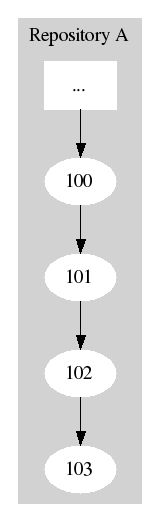
If a new repository is created, we might prefer to start by replicating only the latest version, on the theory that development will primarily move forward:
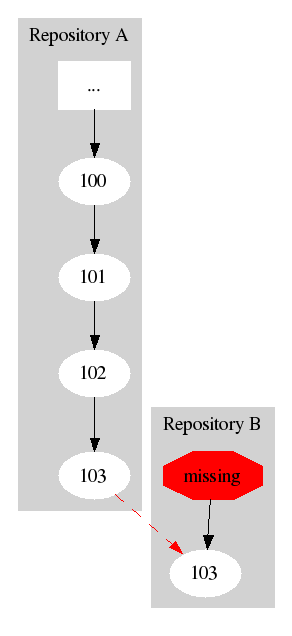
If then later someone at repository B wanted to replicate something from a branch off an earlier version, they would need to get some additional history:
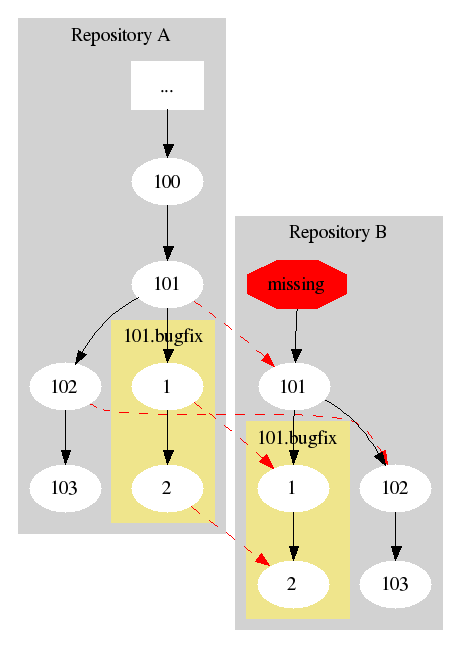
This should work as long as there is sufficient history available when one repository wishes to replicate from another. Suppose there are two branches that each started from a different point on the main line. Suppose these are in two different repositories which each contain the history of those branches, but noting in the trunk other than the version from which they started:
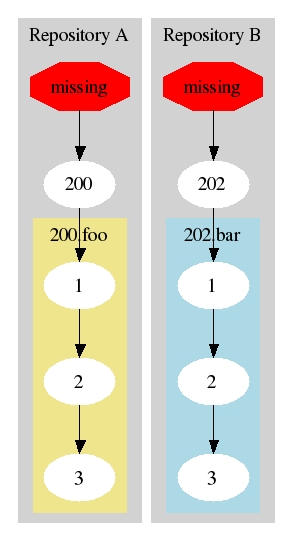
If one of these two repositories wanted to replicate the branch from the other one, there wouldn't be sufficient history to connect the two branches. Presumably somewhere there's another repository which contains versions 200, 201, and 202 which could connect these two:
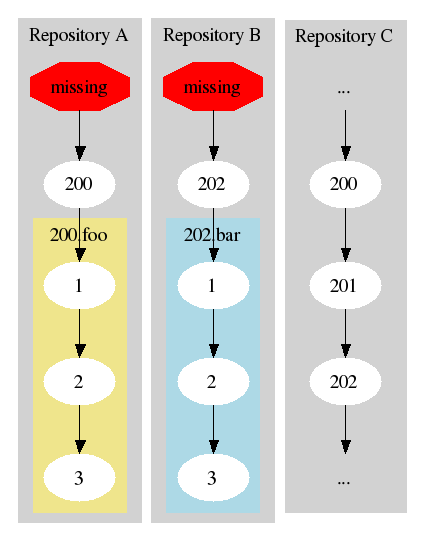
If repositories A and B could replicate those versions from repository C first, then their histories could be connected. But what if repository C is inaccessible? What if it has gone permanently off-line?
Perhaps this is unlikely to come up in practice, but it's a situation that's worth considering.
Relationship to File/Directory Rename/Identity Tracking
The way that file/directory identity is represented can impose constraints on whether history needs to be replicated. See MergingFuture/Food4Thought/RenameTracking.