Contents
Introduction
Monotone is a free software revision control system.
It was one of the first (possibly the first?) to use the concept of referring to revisions by cryptographic hashes of their contents and ancestry. Some people have used the term "chained hash version control" to refer to this idea. Other examples include git (arguably inspired by monotone in many ways) and Codeville.
File Store
Similarities
Both Vesta and monotone store versions of files as immutable objects which can be rferenced by a handle.
Both associate a large number with each file version by which it can be identifed. monotone uses the well-known SHA1 hash function. Vesta uses it's own fingerprinting algorithm.
Differences
While files in Vesta can be referenced by 128-bit fingerprints, they are much more often referenced by 32-bit "short ids". These are essentially a pointer into the local repository's file storage pool and are not portable across different repositories. However, they obviously take up far less space. This is an important concern for Vesta, as it keeps all directory representations of all immutable versions and all working copies in memory. Also, shortids are used for derived files produced by the build system, and storing and transmitting sets of them is an area of concern for efficiency.
In contrast, monotone refers to files only by 160-bit SHA1 hashes.
Vesta may assign files fingerprints based on their contents, but it is not required to. (See the descirption of vadvance's -F flag.) In contrast, monotone always comptues the SHA1 hash of every new file.
History Storage
Similarities
Both Vesta and monotone store versions as immutable objects. Once cretaed, they cannot be changed.
Both associate a large number with each revision by which it can be identifed. monotone uses the well-known SHA1 hash function. Vesta uses it's own fingerprinting algorithm.
Differences
For each revision, monotone stores both a complete record of the entire contents (called a manifest) and the changes made to transform the old version into the new version (sotred as part of each revision record). The manifests are redundant with the changes, as the manifest for a revision can be rebuilt by applying the changes starting from the beginning of time. Note that the record of changes can include information which cannot be computed simply by comparing two manifests, such as "file A was renamed to B".
In contrast, Vesta stores directory contents as either a delta from a previous version or a complete copy. When a new version is created locally, it is always stored as a directory delta. When it is replicated from a peer repository, it is replicated as a directory delta if the previous version already exists at the destination or as a complete copy if the previous version doesn't exist at the destination. Furthermore, the Vesta repository treats directory deltas more as a storage optimization than as a historical record. In certain cases, parts of the deltas can be discarded. The only guarantee that the repository provides is that as long as there is a reference to a particular version in its virtual filesystem, it will retain the complete contents of that revision.
Essentially, the Vesta repository is more a filesystem than history store. This is a problem for advanced merging, as most algorithms do need to know the exact changes between each version along the path from the two versions to be merged and one or more common ancestors.
Having both types of records in monotone provides the added benefit of being able to perform internal consistency checks, avoiding potential bugs in the delta application code. While the changes cannot be derived by comparing complete revisions, the next revision can be derived by applying a set of changes to the old revision's manifest. Also, since monotone uses cryptographic signatures it's desirable to have a direct representation of what a user is attesting to. The manifest provides a direct representation of what the user is signing, which may be easier to trust than the changset data structures and the code which can apply changesets to produce a particular revision.
Here's a brief comparison of the kinds of records in monotone revisions and Vesta delta directories:
monotone |
Vesta |
Files/directories deleted |
Directory delta entries with the VestaSource::deleted type |
Files/directories added |
Directory delta entries |
Files/directories renamed |
Both a deletion and an addition (notably a problem for merging |
Files modified |
Directory delta entries shadowing ones in the old version |
File/directory attribute changes |
For executable flag changes, acts a file replacement. Otherwise, no similar record. |
Another notable difference is that Vesta only stores directory changes as a strict tree, whereas monotone stores revisions as a DAG. Vesta's filesystem approach is apparent here: a single delta representation over a single earlier version is sufficient to represent the contents of an immutable directory. In contrast, when a merge occurs monotone records two different set of changes in the revision record, one for each of the versions being merged.
A subtler difference is that in the Vesta repository internally there's no difference between an immutable directory that's a sub-directory of a particular version and the immutable directory representing an entire version. (There are even some tricks which take advantage of this: RepositoryTricks/SubdirOldVer, RepositoryTricks/LinkIntoWorkDir.) In other words, Vesta has no data structure to represent the entire package. In contrast, monotone revisions and manifests are concerned with the entire directory tree for the revision in question. This helps facilitate merging directory structure changes as the revision-level data structure can record "a/b was renamed to c/d". In Vesta we've discussed a mechanism for storing that information as attributes on a revision, but I no longer think that's a viable approach. The rename information really needs to be stored immutably and in such a way that it is indivisible from the rest of the changes.
While Vesta can refer to revisions by 128-bit fingerprints, they are more often referenced by a canonical path under the /vesta virtual filesystem. This is made portable across repositories through the concepts of mastership and replica agreement. (See "Vesta Replication Design" on the vrepl man page and "Partial Replication in the Vesta Software Repository".) Furthermore, the fingerprints of individual revisions are usually assigned by fingerprinting the text of the canonical path where they were first inserted into the repository (normally with vadvance) rather than by their contents. In contrast, monotone only refers to revisions by their SHA1 hash, and the SHA1 has is computed from the contents of the revision record.
Revision Attributes
Similarities
Both systems allow essentially arbitrary name/value pairs to be associated with revisions. Both use these for storing informaiton like authorship and checkin comments.
Differences
Montone stores such data as cryptographically signed certificates. This means that each one is verifiably added by a particular user, which makes for a useful audit trail.
Vesta stored them as mutable attributes. While a history of attribute changes is retained, the user responsible for attribute changes is not traceable.
Merge Technology
Mark Merge
The monotone developers have done a fairly substantial redesign of their algorithms for merging directory structure changes. The current implementation is based on an idea called MarkMerge. This is a promising area for investigation and possible adaptation for use in Vesta.
To facilitate the mark merge algorithm, montone currently stores with each revision the "marked" parent revisions for each path change (rename) and each content change (file edit). These are stored in what monotone calls a "roster", which is essentially a manifest plus additional information. This avoid the need to traverse the revision DAG on a merge operation, though it does take up additional space.
Monotone's rosters also store a unique ID with each file/directory. This is assigned when the file/directory is created and follows it through any renaming. This makes several other operations by again avoiding the need to traverse history. For example, two rosters can be compared to determine the set of changes required to turn one into another, including renaming. Also, when performing a merge operation it's trivial to find the current location of a file/directory regardless of how many times it has been renamed.
It's worth mentioning that the marked revisions and file/directory node IDs stored in the rosters are purely an optimization. They could be recomputed by traversing the history. Also, this information is purely local to each monotone DB; it is not transmitted when communicating with peer DBs in push/pull/sync operations.
Roster Example
Here's an example stanza from a monotone roster:
file "botan/mem_pool.cpp"
content [cc2313bdb2ed78668efea720ddd78929c8afb461]
ident "2656"
birth [b2a85983739b31bd01969cc21d510a2c9a656252]
path_mark [b2a85983739b31bd01969cc21d510a2c9a656252]
content_mark [2e68909d3d85d4fbc8a2481c1b3158a138e4d45f]
content_mark [53785231cf54192a449c378a6120313b3e842890]Things to note:
- It's birth revision and path_mark revision are the same. This tells us that it hasn't been renamed since it was initially created.
It has two different content_mark revisions. (See the description of multi-mark-merge for how this can happen.)
File Life-cycle
In monotone, in a given revision a file (or a directory) can be in exactly one of three states:
Unborn: the file has not yet been created (e.g. it's creation is in some future revision or in a different branch)
Alive: the file exists (it was created in some ancestor revision and has not been deleted)
Dead: the file has been deleted (in this revision or some ancestor of it)
As history advances, files can only ever change from Unborn to Alive and from Alive to Dead. That is, once a file has been deleted it stays deleted forever. There is no way to "resurrect" a deleted file. If a file with the same name is created in a later revision, it is a different file (i.e. has a different file ID).
This approach, which is used by other systems, is sometimes called DieDieDieMerge. It's a useful simplification, both for the implementation and for the user, but it has some implications which are worth mentioning:
A file deletion in any branch dominates when merging. That is, if user A modifies a file and user B deletes the file and they merge, the result is that the file is deleted. (In fact, monotone will currently silently drop the changes made in parallel to the deletion, though it would be possible to detect that and warn about it.)
- If a file with a particular name is deleted and re-created, because its unique file ID is different they are treated like two different files. Changes made to the old file will never be merged into the new file.
I believe that some other systems support resurrecting a deleted file, but that has some implementation complications which the method used by monotone avoids. (For example, if there are multiple un-merged variants of a file before it gets deleted, all of those different file contents would need to be remembered and merged if the file is ever resurrected.)
Directory Structure Conflicts
Monotone has arguably one of the more sophisticated systems for tracking and merging directory structure changes. Here are the kinds of conflicts their directory structure merger can recognize:
Name conflict: File/directory has two different names. Caused by merging "rename A->B" with "rename A->C".
Rename target conflict: Two different files/directories renamed to the same name. Caused by merging "rename A->B" with "rename C->B".
- Note that this also covers an unusual case where there are two distinct directories which are both trying to become the project root.
Orphaned node: Parent directory no longer exists. Caused by merging "create A/B" with "rmdir A".
Directory loop: Combining two renames would create a directory loop. Caused by merging "rename A->B/A" with "rename B->A/B".
There are also some other more monotone-specific conflicts that come out of the same merge algorithm:
Illegal name: Trying to place a file/directory with the reserved name "_MTN" in the project root. I believe this can be caused by merging the creation of that name in a subdirectory with an operation which changes which directory is the project root.
- Node attribute conflict: Monotone allows arbitrary attributes to be attached to versioned files, and changes to those attributes are versioned and merged. This can produce conflicts as well.
Pluck
monotone also has a feature called pluck which may be worth adapting. It does its best to intelligently apply changes in a different context from the one in which they were originally created.
It works by creating a fake revision graph that looks like this:
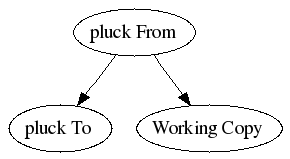
It then performs a merge operation to create a new fake revision:
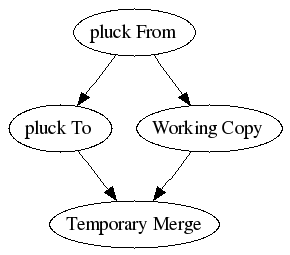
It then applies changes to transform the working copy into the merged state.
This uses montone's normal MarkMerge code and its directory structure merging and conflict resolution but in a somewhat degenerate way as this really just a 3-way merge (treating the "from" revision as the common ancestor).
This is enabled by monotone's roster format and its tracking file/directory identity. This makes it possible to construct the fake revision graph by directly comparing the "from" state with both the "to" state and the working copy to get two sets of changes to combine.
Other Random Observations
monotone-viz is a very cool way to look at history in monotone. If there's a single GUI I'd want to steal, that would be it.
A number of the things I've written about (vupdateandbranches) and even implemented in scripts (DevelopingVesta/BranchStatus) seem to me like they're reaching for something more like monotone's concept of branches and automatically finding the current heads. However, I would mention that finding the current heads of a branch in a significant repository does seem to have a noticeable time cost.
The output of "mtn status" is kind useful in that it tells you about everything which has changed since the previous revision. It's a little more readable than the output of "vdiff -q", which is what I tend to use for that. It wouldn't be hard to write a utility that did something more like "mtn status" for a Vesta working directory.
One thing that strikes me as really convenient about the monotone UI is that it remembers the last value you used for quite a few things (database, remote server for sync, branch to commit to or sync, etc.) and makes those the default for subsequent operations. Off the top of my head I'm not sure what we could automatically remember in that way, but it's a neat trick.
Another nice thing: you can supply a checkin comment before commit by sticking it in the file "_MTN/log". You could sort of do that by changing the "message" attribute on a version reservation stub, but it's not that easy to edit attribute values. Hmm... maybe vattrib could have a mode where it invoked $EDITOR to let you edit an attribute value, though I don't know how you would handle multiply-valued attributes.
Monotone includes code in its scripting extension lanague (Lua) to invoke several different interactive merging/conflict resolution tools including:
If the user doesn't explicitly specify which of these tools they would like to use, the Lua code tries to make an educated guess based on the $EDITOR environment variable (picking either Emacs or vim).