Contents
(This design borrows some ideas from BitTorrent. You may want to read "How BitTorrent Works" if you're not already familiar with that protocol.)
(JoeLee deserves credit for first pointing out that the problem of distributing immutable files to a large number of clients is very similar to the problem BitTorrent was designed to solve.)
An Opportunity
A basic fact of a multi-client Vesta installation is that the contents of immutable files (both source and derived) exist on multiple hosts.
- When a source file is read by a tool during a build, its contents exist in the NFS client cache on the host running the tool.
- When a derived file is written by a tool, the contents of the file exist in the NFS client on the host running the tool
- When a build result shipped as symlinks is read by a client, the file's contents exist in the NFS client cache on the host using the build result
Because we're using NFS to a single server (both to the repository's virtual filesystem and for the shortid pool which builds shipped as links point into), any client which does not have the contents of a file go through the server. When there are many clients and lots of files being accessed, this can require a lot of server resources.
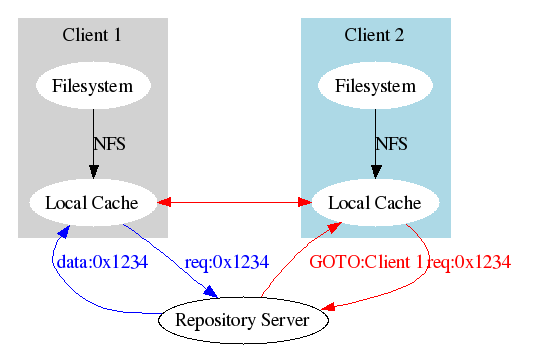
The fact that so many files are immutable give us an opportunity for optimization. If we change network protocols (i.s. stop having all clients access one central server via NFS), we could take advantage of the fact that the same data exists in multiple places. When a client needs a file that another client already has, it could retrieve it from that client rather than from the central server.
Immutable Shortid Cache
The first step is to take control of the caching of immutable file contents on the client hosts. (While the NFS client cache provides a similar capability, it's essentially opaque and outside our control, not least of all because there are multiple different NFS client implementations.)
We would want to use the same 32-bit shortids for identifying files as is used in the repository, evaluator, and build cache. Also we would only cache the contents of immutable shortids on clients.
This local cache of immutable shortids would be made available on the client through a virtual filesystem. There are at least two ways we would want to do this:
As an alternative to accessing the shortid pool over normal NFS. This would facilitate the evaluator's -s (ship as symlinks) flag. An attempt to access a shortid through this interface would trigger retrieval of the shortid contents.
(Note that since this would only support immutable shortids, it would not work as a complete replacement for the current evaluator's access to the shortid pool over normal NFS, as that includes writing files. We've already been working on changing the implementation to avoid the need for that.)
For the volatile directories used when executing tools. This would require moving the serving of volatile directories out of the central repository server and into the RunToolServer on each client.
Locally caching the input files for each tool run could provide better performance than the current implementation. The repository does actually play tricks with the NFS filehandles to try to take advantage of the NFS client read cache across multiple tool runs on the same host, but these can only be used under the right conditions (when the existing_writable argument to _run_tool is false) and we have no control over how much data is retained or for how long.
- Keeping a cache of result files after they have been completely written would provide an alternate source for the file contents if a subsequent build step using it should run on a different client
Once a client has a copy of an immutable shortid, it would also make it available to peer clients.
Shortid Availability Tracking
The repository server would need to keep track of which clients have copies of what immutable shortids. In BitTorrent terminology, it would act as a tracker.
When a client needs a copy of a shortid, it asks the repository server for a list of other peers which have it. The server gives the client that list. The client then contacts one of those peers to get a copy of the file.
The server should also give out additional information about the file (the timestamp, size, and checksum) so that the data retrieved from the peer can be validated.
In the event that no peer has the file, it obtains a copy directly from the server. The server then remembers that the client has the file.
If a client contacts a peer to obtain a file and has trouble (connection refused or timed out, the peer claims not to have the file, the peer sends data with a bad checksum), it will inform the server so that it can be removed from the tracker.
Possible Improvements
There are a few things which would not be strictly necessary but which we may want to consider along with this.
Compression
This could actually help with implementing compression of the repository's file store. One problem with compression is the significant additional CPU load it could place on the central repository server.
Since the clients would be mediating access to the shortids in most cases, we could have the decompression performed on the client end.
For derived files, if the volatile directory serving is performed on the clients and result files are only sent back to the server once they've been fully written, the client could compress them first. This would distribute the compression work as well.
Limiting The Size of the Client Cache
Suppose a client is running a tool that reads large number of files, or is using a build result shipped as links that contains many files. Should it cache all of them locally? That would probably be the most straight-forward approach, but that could result in a large amount of data being cached on each client and in many duplicate copies of the same file.
Another alternative would be to allow one client to perform read-through from a peer without caching its own copy. We might also need to allow read-through directly from the server if we want to put a strict limit on the size of each client's cache.
Another way we might want to tune the caching is to set a target number of clients to cache each shortid. If a client finds that fewer than the target number of clients have cached a shortid, then it would also cache a copy of it. Otherwise it could do read-through from one of the clients that has a copy of it.
Implementation Wrinkles
There are a few tricky parts to implementing this.
Weeding
When weeding occurs, each immutable shortid cache will need to perform the same shortid deletions as the repository server.
The repository would have to broadcast the set of shortids to keep and the associated keep time to all clients running an immutable shortid cache. They would then each need to drop and shortids not on that list and older than the keep time.
This means that clients will need to keep the correct modification time of immutable shortids in addition to their contents.
Client Startup
When a client starts up its immutable shortid cache, it has no way to know whether a weed has happened since it was last running. This means that some of the immutable shortids it cached locally when it was last running may no longer be valid.
Therefore, it must discard all previously cached immutable shortids.
Well, we could improve on that some. The repository could keep a weed generation number, incremented each time a weed is done. Then if we're still in the same generation number when a client starts/restarts as when the client last ran, the client can keep its cache. --TimMann
Repository/Tracker Server Restart
If the repository server restarts, what are the consequences for the immutable shortid cache?
It's tempting to think that it can keep the files it had cached before the server went down and simply reconnect and send the set of files it has to re-initialize the tracker. However there could be a race between clients reconnecting and weeding which would leave some with invalid shortids cached.
A conservative approach would be to simply drop all cached shortids when the repository server restarts. However it would be nice if we didn't have to invalidate the entire cache.
Another possibility would be to have the client when reconnecting with the restarted server have its set of currently cached shortids re-validated. This could be done through a checksum of the contents of each (plus the timestamp which we know needs to be kept for weeding).
Note that in order to implement this, the local caching agent will need to pay careful attention to network errors when communicating with the repository/tracker server.
Same comment here as on client startup above. --TimMann
Small Vesta Installations
It's possible to run Vesta with a small number of clients, even a single machine installation. Some people run Vesta on laptops.
We definitely need to ensure that there's some way to disable client-side caching of shortids when the client and server are the same machine. We should probably also allow it to be turned off for installations with a small number of clients, or for clients with resource restrictions (e.g. a lack of disk to use for locally caching immutable shortids).
Assuming that we allow read-through from the server when limiting the size of each clients cache, we could simply set the maximum client cache size to zero for the single-host case, switching it always read through from the server. We would want to ensure that the read-through from the server was very efficient to try and avoid degrading performance in the single-host case.
Tolerating Flaky Peers
What if a peer falls off the network? What if it is heavily loaded such that it has difficulty serving out a file? What if it accepts the connection but never answers the RPC requesting the file? (Some versions of the Linux kernel can get wedged and do this, apparently never scheduling the listening process.)
We need to take care to make sure we tolerate cases like this.
One way we might do this is have a client send requests to multiple peers that have a copy of a file. If a client was going to cache a copy of a shortid, it could ask one peer for the first half of the file and another for the second half of the file in parallel (i.e. in two different threads). If one of them has failed to respond by the time the other has, then it could be declared dead. One could even use more peers and smaller pieces of the file for large files.
However, if a file is retrieved piecmail and re-assembled and then turns out to have an incorrect checksum, it could be tricky to determine which piece or pieces of the file were bad. There are methods for dealing with this (hash tries, and I believe rsync has a method for determining which portion of a file is different) which we might need to use.
Limited Prototype
We could build a relatively limited prototype version of this that runs separately from the repository. The server side would implement the tracker functionality and serve out copies of any shortids that are already immutable (based on their on-disk permission bits). The client side would present a virtual filesystem that's equivalent the sid directory and perform local caching of immutable shortids.
This would only be useful for a read-only shortid pool that could be pointed to by a build shipped as symlinks. However the server and client sides could be separate from the Vesta repository.
The only code change which would be necessary would be adding a feature to the evaluator which would change the shortid directory that results shipped as symlinks pointed into.
This would lack some advantages of a more complete solution. It would not provide any speedup for running tools during building. Building would also not automatically seed the client running the tool with a copy of the derived files it writes. However it would be significantly easier to put this together and could allow us to get a rough idea of how effective the technique would be.
Weeding would be a minor problem. We would probably need to force a restart of the server end when weeding, using one of the methods described above for handling server restart.
We now have the beginning of such a prototype:
/vesta/beta.vestasys.org/vesta/extras/p2p_sid_prototype
Information for Users/Administrators
The main decisions you need to make are:
Where will the file caching agent store its local copies on each machine? You specify this with the [ShortidCache]dir setting in vesta.cfg. If /tmp has enough space, you can just put it there. (Make sure you pick a directory local to each machine.) Nothing needs to be saved across reboots or restarts of the file caching agent. It will work just fine if you delete the files it places there (while it's not running).
How much disk space do you want it to use for local cached copies of files? You specify this with the [ShortidCache]disk_limit setting in vesta.cfg. You can give a number of bytes with an optional multiplier (k, M, G) or as a percentage of the total size of the filesystem containing the local cache. If not set, it defaults to "10%". (If you pick a size larger than the space available on the disk, the file caching agent will still do its best not to fill it up completely.)
Where do you want to mount the virtual filesystem provided by the file caching agent? You specify this with the [ShortidCache]mount setting in vesta.cfg. Normally you and should make this end in "/sid" and set [Evaluator]symlink_sid_root to the part before the "/sid" for users who want to use the file caching agent with builds shipped as symlinks. (You'll need an evaluator with support for [Evaluator]symlink_sid_root to use this. release/12.pre13/10 was the first pre-release to include that feature.) For example:
[ShortidCache]mount = "/tmp/.p2p-vesta/sid"
[Evaluator]symlink_sid_root = "/tmp/.p2p-vesta"
See the "examples" directory in the package of the prototype implementation. In there you'll find:
A sample vesta.cfg with explanations of all the settings
A script to start the file caching agent and mount it automatically at boot time and a file of settings to control the boot-time script
Protocol Notes
This section contains some notes on the different network protocols needed to implement this. Unless we have a reason to do something different, these will be implemented over TCP as remote procedure call protocols using the SRPC library which is used by other components of Vesta.
For comparison and reference: the BitTorrent protocol specification.
Central Tracker Server
This protocol will be used by the peer file caching agents to communicate with the central server. It's used for:
- The initial download of a file when no peers can provide a copy
- Maintaining the lists of peers which have copies of each file
- Allowing one peer to locate other peers which have the files it needs
File Request
This is a request from a client for a file which they need.
Client sends:
- The shortid they need.
- The port they listen on for requests from peers
- The IP address from the client end of the RPC is combined with the port for a full address
Server responds with:
The type of response, which is one of: No Such File, File Contents, or Peer Set
If the response is No Such File no other data is sent
If the response is File Contents, the server then sends:
- File attributes
- Size in bytes
- Modification time
- Executable flag
- A data block size
- A sequence of blocks (the entire file), each with:
- A block hash (currently using the fingerprinting algorithm used by other parts of Vesta)
- A sequence of bytes (the data in the block)
- File attributes
If the response is Peer Set, the server then sends:
A sequence of peer addresses, each as IPv4 IP:port addresses
- File attributes
- Size in bytes
- Modification time
- Executable flag
- A data block size
- A sequence of block hashes
The server chooses to send the file contents when the number of clients it knows of is below a certain threshold (defaulting to 3). This ensures that when the server responds with a peer set that there are multiple peers for the client to contact. (See Tolerating Flaky Peers above.)
A hash list is used to allow clients to independently verify individual data blocks retrieved from peers. The server chooses the block size which clients must then use when communicating with peers. (Note that small files may be just one block.)
When sending file contents directly, the block hashes are sent as part of the sequence of block data. (That is, the first block hash arrives , followed by the first block's data, followed by the second block hash, followed by the second block's data, and so on.) This allows the server to compute the block hashes as it sends each block, avoiding the need to read the entire file twice.
If the server chooses to send the file contents, it immediately adds the clients address to the set of peers believed to have a copy of the file so that it can give their address to other clients requesting the file.
Have File
This is an indication from a client that they have retrieved a file from their peers and request to be added to the tracker so that other clients can get the file from them.
Client sends:
- The shortid they have
- The port where other peers can call them to retrieve it
- The IP address from the client end of the RPC is saved with the port
- File attributes
- Size in bytes
- Modification time
- Executable flag
- A data block size
- A sequence of block hashes
The server responds with a boolean indicating whether the client was added to the set of peers believed to have a copy of the file. Obviously the server will only add the client if the file attributes and block hashes sent match the information which the server has about the file.
A well-behaved client is obligated to discard its copy of the file and not provide its contents to peer if the server indicates a mis-match.
It is possible that the server has no record of the file and yet the client's copy is valid. This could be cause by a race between all the peers the server knows of dropping the file and the client that just obtained a copy from them telling the server that is has a copy of it. The server could read the file from disk and check the block hashes to validate the client's copy, or it could simply respond in the negative and force the client to re-request the file.
Note that the client does not need to make this call when the server immediately sends a file to them in response to a file request. In that case, the server automatically adds the client to the known peer set.
Drop File
This is an indication from a client that they are discarding a file from their local cache and will no longer be able to provide its contents to other peers.
Client sends:
- The shortid they are discarding from the local cache
- The port where other peers can call them to retrieve it
- As with the "File Request" and "Have File" calls, the IP address from the client end of the RPC is combined with the port to get a full address
The server response is empty. (It could send an error if the IP:port was not in the tracker for the file, but it can also just ignore that case.)
Bad Peer Report
This is an indication from a client that they contacted another peer with a file requests and either they said they didn't have it or a network error prevented the request.
Client sends:
- The shortid they were looking for
The peer IP:port they tried but couldn't get it from
Server response is empty. Note that the server responds immediately and queues this shortid/IP:port to be checked in the background
If the IP:port is not in the tracker for the given shortid, no action is necessary. If it is in the tracker, it is immediately dropped to avoid sending a bad peer to other clients (especially to the same client). In the background, a request will be made to the peer to see whether it has the file and should be added back to the tracker.
The client could additionally send what went wrong (connection refused, connection timed out, successful RPC but negative response, successful RPC but data hash mismatch). The server could then avoid making a "File Check" RPC to the client in the event of a network error. However this requires trusting the report as valid, so maybe it's a bad idea.
Peer Restart
This is an indication from a client that it is starting up right now. This means that they have no shortids cached, and if they are listed in the tracker for any shortid they should be removed from it.
Client sends:
- Their port
- Again, combined with the IP of the client end for a full address
Server response is empty. Note that the server responds immediately and queues this IP:port to be removed from all file trackers in the background.
Block Request
This is a request from a client for a single block of a file. The server responds with the data from that block and a (possibly empty) set of peers believed to have a copy of the file. This is needed to guarantee forward progress, as the client could have received a non-empty peer set just as those peers were dropping the file. When a client runs out of peers to try, it uses this call to get at least some data plus a new peer set.
Client sends:
- The shortid they want one block of
- A byte count and byte offset within the file
Server responds with:
The type of response, which is either No Such File or File Contents
If the response is No Such File no other data is sent
If the response is File Contents, the server then sends:
- A block hash (currently using the fingerprinting algorithm used by other parts of Vesta)
- A sequence of bytes (the data in the requested block)
A possibly empty sequence of peer addresses, each as IPv4 IP:port addresses
Note that we could do away with the File Request call in favor of using just this one by changing its result to include the file information and block hashes, or have File Request only send information, block hashes, and a peer set. From a bandwidth standpoint it is a little attractive to have the first client to request a file get the entire file in a single request, but it makes it more difficult for the client to prioritize its work based on incoming filesystem reads.
Should the server require that the requested byte range corresponds to one of its blocks in the hash list it sends out in response to File Request calls? If so, the client could just send a block index. If not, the bytes requested could be placed arbitrarily (which would prevent the server from checking their hash against its hash list before sending) and/or arbitrarily large (which could allow for a denial-of-service attack).
Should the client be added to the peer set for this file after we've sent it this block? At that point it has at least one block which it could send to peers. If we do that we should change the protocol for the peer-to-peer file request call to allow a peer to answer with "I only have part of that file, and not the part you aksed for" possibly along with "but here's the contents of a block I do have".
Caching Agent
This protocol would be used to make requests of the peer file caching agents. It's presented here as a single RPC protocol, though some calls would be used by peers and some by the tracker server.
File Request
This is a request from a peer caching agent for one block of a file which they need. (Presumably the central tracker told the peer that we have it.)
Client sends:
- The shortid they need.
- File attributes from the server:
- Size in bytes
- Modification time
- Executable flag
- A byte count and byte offset within the file
- A hash for the block being requested
Server responds with one of:
The type of response, which is one of: No Copy Here, File Contents, or Attribute Mismatch
If the response is No Copy Here no other data is sent
If the response is Attribute Mismatch no other data is sent
If the response is File Contents, the server then sends a sequence of bytes (the data in the requested byte range)
If the response is No Copy Here, the client should report this to the tracker with a "Bad Peer Report" RPC.
If the response is Attribute Mismatch, the client should report this to the tracker with a "Bad Peer Report" RPC and the peer should re-validate its copy against the the tracker with a "Have File" RPC.
Allowing retrieval of one block supports two things:
Reading from multiple peers in parallel to tolerate peers listed in the tracker that fail to respond (see Tolerating Flaky Peers above) and to distribute the request load across multiple peers.
- Servicing a filesystem read from an NFS client without caching a local copy.
Note that if the client retrieves the entire file and caches a local copy of it, they should report this to the tracker with a "Have File" RPC.
We should change this call to have the server send back the file attributes and the block hash, having the caller do the attribute validation (which would put less trust in the peer).
File Check
This is a request from the central tracker to check whether this client has a valid copy of a file or not. This would be initiated by a "Bad Peer Report" RPC from another peer.
Client (actually the tracker) sends:
- The shortid in question.
- File attributes:
- Size in bytes
- Modification time
- Executable flag
- A data block size
- A sequence of block hashes
Server responds with either success (indicating that it does have the file and the attributes and clock hashes match) or failure (indicating that either it does not have the file cached or a mismatch on file attributes or block hashes).
In the event of a file attribute mismatch, a well-behaved server is obliged to drop the cached copy of the file (as it's incorrect).
A well-behaved server should re-compute the block hashes from it's on-disk copy of the file to protect against it becoming corrupted behind its back.
We should change this call to have the server send back the file attributes and the block hashes, having the caller do the attribute validation (which would put less trust in the peer).
Weeding
This is an indication from the tracker that weeding is taking place and that files not being kept should be dropped from the local cache.
Client (the tracker) sends:
- A list of shortids to be kept (the "keep list")
- A timestamp (the "keep time")
Any files not in the keep list and with a modification time before the keep time should be dropped from the local cache.