Contents
- Introduction
-
Statistics
- PKFile size (in bytes)
- Number of free variables per PKFile
- Number of common free variables per PKFile
- Percentage of common free variables per PKFile
- Number of cache entries per PKFile
- Number of total free variables per cache entry
- Number of uncommon free variables per cache entry
- Percentage of uncommon free variables per cache entry
- Cache value size (in bytes)
- Number of derived indices (DI's) per cache value
- Number of child entries (kids) per cache entry
- Size of the cached value's PrefixTbl
Introduction
The Vesta cache can be thought of as a custom database. The structure of the data stored there and the way queries are made to it are defined by the SDL code. As with most programming tasks, there are many different ways to write an SDL program to accomplish the same goal. Some ways are more are more efficient and some are less efficient.
VCacheStats is a utility for gathering and printing statistics about the contents of the Vesta cache. Those statistics can be used as feedback to improve the efficiency of your SDL code.
Before you try to use VCacheStats, you should understand the basics of HowCachingWorks, including:
The difference between the PrimaryKey and secondary dependencies
- The different kinds of secondary dependencies
- The organization of the cache into MultiPKFiles, PKFiles, common fingerprint groups, and cache entries
Methods to control caching behavior including how dependencies are recorded bu the _run_tool primitive function
How to use PrintMPKFile and read its output to get detailed information about the contents of the cache
DevelopingVesta/PkFileEvolutionExample shows several examples of its output with some explanations
You may also want to look at CacheUnderTheHood.
The rest of this page explains statistics that VCacheStats reports, and how to improve functions that you find using VCacheStats.
Statistics
PKFile size (in bytes)
All entries with the same PrimaryKey are stored together in a PKFile. The size of a particular PKFile gives you a rough indication of the total amount of data stored for all the entries of that PrimaryKey. It also indicates the amount of data that may be read into memory for that PrimaryKey.
Large PKFiles can obviously take up disk space. They may also cause the cache daemon to use a large amount of memory.
How to Improve
A large PKFile could indicate any one of several things:
A PrimaryKey with a large number of cache entries
- See also the statistic "Number of cache entries per PKFile"
A PrimaryKey with a large number of secondary dependencies
- See also the statistic "Number of free variables per PKFile"
A PrimaryKey with large cached values (i.e. composite SDL values with many sub-values)
- See also the statistic "Cache value size (in bytes)"
What can you do about these things?
Move secondary dependencies into the PrimaryKey to divide up cache entries into more PKFiles
- Change the function to return smaller values
- Reduce the number of secondary dependencies of the function
Suppress caching of the function with /**nocache**/
Number of free variables per PKFile
Free variables (also known as secondary dependencies) are the set of values that must match for a cached result to be re-used. They are recorded dynamically as a function call is evaluated, so they represent exactly what values the function actually used. (See HowCachingWorks for a more detailed explanation.)
The set of free variables in a PKFile is the union of all the sets of free variables of each of the cache entries for the PrimaryKey of the PKFile. When the evaluator performs a lookup for a particular PrimaryKey, it must supply values for all the free variables which all the cache entries for that PrimaryKey depended upon.
The amount of work that the evaluator and the cache server daemon must do to perform a cache lookup is proportional to the number of free variables in the PKFile. The more more free variables a PKFile has, the more work both the client and the server must do to search for a matching cache entry. Reducing the number of free variables will make cache lookups more efficient.
Free variables also consume network bandwidth during a cache lookup. The cache server must send the set of free variables to the client, and the client must send back the fingerprint of the corresponding value for each. So reducing the number of free variables reduces network utilization.
The free variables also take up space in the PKFile on disk, so this is related to the statistic "PKFile size (in bytes)".
How to Improve
The simplest way to reduce the free variables of a PKFile is to move those values into the PrimaryKey. This has the added benefit of splitting up cache entries into more PKFiles, which means fewer entries need to be considered when searching for a match.
For user-defined functions in SDL, you use the /**pk**/ pragma on function arguments to include them in the primary key. (See "Controlling Cache Behavior" in the programmer's reference and the description of pragmas in the vesta(1) man page.) Remember that if you apply the /**pk**/ pragma to arguments which the function doesn't necessarily use, you may cause false cache misses. In some cases, you may need to re-factor the SDL code in order to get the right values into function arguments to which you can apply the /**pk**/ pragma. For example, consider this function:
Because only one sub-value from the two binding arguments "b1" and "b2" are used, we don't want to include "b1" and "b2" in the PrimaryKey. Doing that would cause false cache misses in the future if other parts of "b1" and "b2" that the function doesn't use change from one call to another. However we could re-write this function like so:
1 /**nocache**/
2 f(b1, b2, n)
3 {
4 f_inner(/**pk**/ v1, /**pk**/ v2)
5 {
6 return v1 + v2;
7 };
8 return f_inner(b1/$n, b2/$n);
9 };
The outer function has caching suppressed with /**nocache**/ and simply arranges the correct values in the arguments of the inner cached function. Now we can use the /**pk**/ pragma on the two values used by the function.
In some other cases you can reduce secondary dependencies by using a different operators or functions inside an SDL function. For example, when used on bindings the _append primitive function will generate fewer free variables than either the ++ recursive overlay operator or the + overlay operator.
For _run_tool calls, you can use ./tool_dep_control/pk to add portions of the tool filesystem to the PrimaryKey. Of course you can also pass information to the tool through command line arguments, ./envVars (environment variables), or standard input, all of which are always included in the _run_tool PrimaryKey.
You can also use ./tool_dep_control/coarse and ./tool_dep_control/coarse_names to control how _run_tool records dependencies. If there's an empty directory in which a tool writes temporary files with random names, it would be a good idea to record it coarsely with ./tool_dep_control/coarse. Otherwise you can get many free variables from different runs of the same tool picking different random temporary file names. If a directory contains some files which are used by the tool and some which are unused but the tool is also placing files with random names there (or looking for files with random names there) then use ./tool_dep_control/coarse_names instead.
Number of common free variables per PKFile
(to be written)
How to Improve
(to be written)
Percentage of common free variables per PKFile
(to be written)
How to Improve
(to be written)
Number of cache entries per PKFile
(to be written)
How to Improve
(to be written)
Number of total free variables per cache entry
(to be written)
How to Improve
(to be written)
Number of uncommon free variables per cache entry
(to be written)
How to Improve
(to be written)
Percentage of uncommon free variables per cache entry
(to be written)
How to Improve
(to be written)
Cache value size (in bytes)
(to be written)
How to Improve
(to be written)
Number of derived indices (DI's) per cache value
(to be written)
How to Improve
(to be written)
Number of child entries (kids) per cache entry
Cache entries form a call graph. When one cached function calls another, the caller refers to the callee as a child cache entry. (See also GraphLog.) This allows the weeder to keep the entire call graph of a build. (See also HowWeedingWorks.)
If a cache entry has a lot of child cache entries, it means that when a build cache misses on that function it will need to perform cache lookups for all those children. Unfortunately, cache lookups are not free. They take time, network bandwidth, CPU resources on the client evaluating the build, and CPU and I/O resources on the server running the cache daemon. A function with lots of child cache entries may represent an opportunity to eliminate some cache lookups.
How to Improve
One possible cause is a function that uses a simplistic foreach loop or _map/_par_map to process an arbitrarily large number of sub-components. You can solve this by using a BalancedCallTree.
Another possible cause is a function that calls a tree of /**nocache**/ functions which then call cached functions.
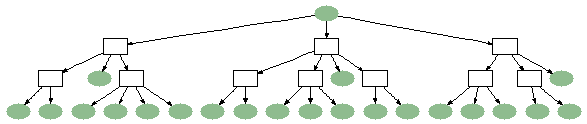

Only the evaluator knows about /**nocache**/ functions; the cache never sees them. The cache only knows about cached functions that call other cached functions. So in a case like this, it looks like one cached function that calls the /**nocache**/ function calls all the leaf cached functions. You may want to consider making some intermediate functions cached to reduce the fanout of the function with the many child cache entries.
Another possible cause is a function that calls the same cached function multiple times:
1 g() {
2 // ...
3 };
4
5 f() {
6 ... g() ...
7 // ...
8 ... g() ...
9 // ...
10 ... g() ...
11 // ...
12 ... g() ...
13 // ...
14 ... g() ...
15 };
The system can't optimize out such multiple calls for you. Each call to the function g causes a lookup to the cache server, including all the costs. So unless the arguments to the called function are changing between calls, it's better to make the call once and save the result:
1 f() {
2 g_result = g();
3 ... g_result ...
4 // ...
5 ... g_result ...
6 // ...
7 ... g_result ...
8 // ...
9 ... g_result ...
10 // ...
11 ... g_result ...
12 };
You can find cases like this when one cache entry has the same CacheIndex listed multiple times as a child.
Size of the cached value's PrefixTbl
(to be written)
How to Improve
(to be written)